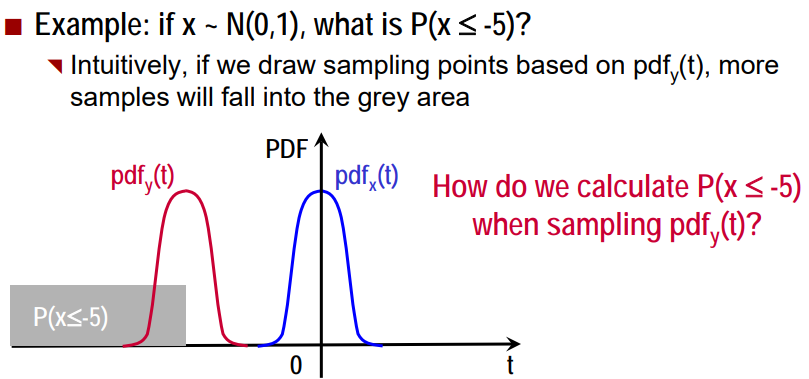
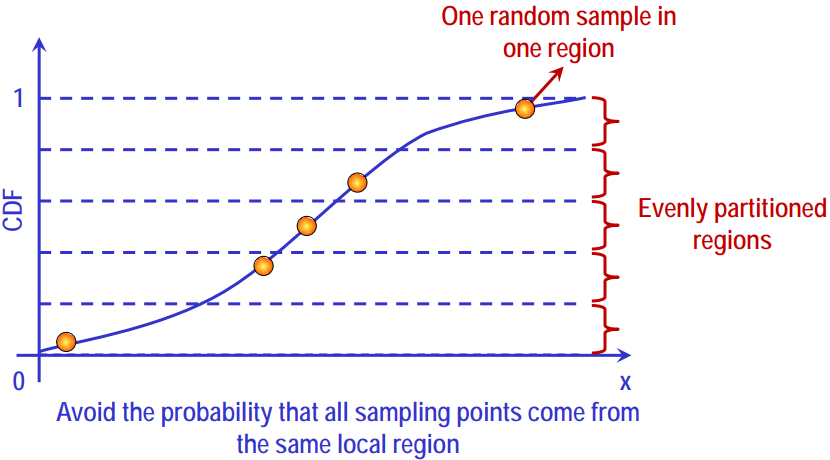
1. Reservoir Sampling 정의 n개의 항목 목록에서 k 개의 샘플을 무작위로 선택하기 위한 무작위 알고리즘으로, 여기서 n은 매우 크거나 알 수 없는 숫자이다. 일반적으로 n은 목록이 주 메모리에 맞지 않을 정도로 크다. 예를 들어 Google 및 Facebook의 검색어 목록이다. 특징 데이터 스트림에서 샘플링하는 알고리즘 2. Process 단순화하기 위해 숫자의 큰 배열 (또는 스트림)이 주어지며 1 < = k < = n 인 k 숫자를 무작위로 선택하는 효율적인 함수를 작성해야한다. 입력 배열을 stream[] 으로 하자. 간단한 해결책은 최대 크기 k의 배열 저장소 reservoir[]를 만드는 것이다. 스트림 [0..n-1]에서 항목을 하나씩 무작위로 선택한 뒤, 선택한 항목이 이..