What is boundary conditions and initial conditions? 1. Boundary Condition 공간(위치 또는 거리)에 대한 설명 영역의 경계에서 함수의 동작을 표현 2. Initial Condition Boundary Condition과 같지만 시간 방향에 대한 것. 시뮬레이션 시작 시점의 조건(t = 0) [참고자료] 1. 3.1: Introduction to Boundary and Initial Conditions - Mathematics LibreTexts 2. 카테고리 없음 2023.02.14
[Sampling] Reservoir Sampling 1. Reservoir Sampling 정의 n개의 항목 목록에서 k 개의 샘플을 무작위로 선택하기 위한 무작위 알고리즘으로, 여기서 n은 매우 크거나 알 수 없는 숫자이다. 일반적으로 n은 목록이 주 메모리에 맞지 않을 정도로 크다. 예를 들어 Google 및 Facebook의 검색어 목록이다. 특징 데이터 스트림에서 샘플링하는 알고리즘 2. Process 단순화하기 위해 숫자의 큰 배열 (또는 스트림)이 주어지며 1 < = k < = n 인 k 숫자를 무작위로 선택하는 효율적인 함수를 작성해야한다. 입력 배열을 stream[] 으로 하자. 간단한 해결책은 최대 크기 k의 배열 저장소 reservoir[]를 만드는 것이다. 스트림 [0..n-1]에서 항목을 하나씩 무작위로 선택한 뒤, 선택한 항목이 이.. Sampling 2023.02.13
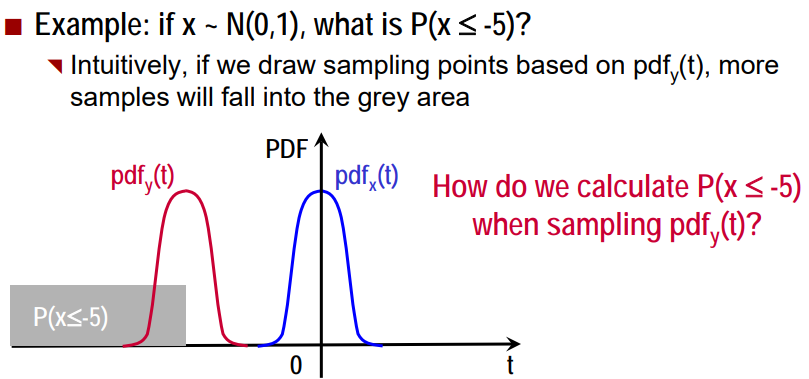
[Sampling] 중요도 샘플링 (Importance Sampling: IS) 1. Importance Sampling 정의 효율적으로 기댓값을 추정하기 위해 고안되었으며, 확률 밀도 추정 및 강화 학습 등의 다양한 활용에 이용 기댓값을 계산하고자 하는 확률 분포 p(x)의 확률 밀도 함수 (probability density function, PDF)를 알고는 있지만 p에서 샘플을 생성하기가 어려울 때, 비교적 샘플을 생성하기가 쉬운 q(x)에서 샘플을 생성하여 p 의 기댓값을 계산하는 것 즉, pdf(p(x))로 임의의 샘플을 생성하지 않음. Monte Carlo sampling 정확도를 향상시키기 위해 왜곡된 pdf(q(x))를 찾는다. 활용 예 어휘량이 많은 neural language models의 학습을 가속화하기 위해 Estimate partition function .. Sampling 2023.02.13
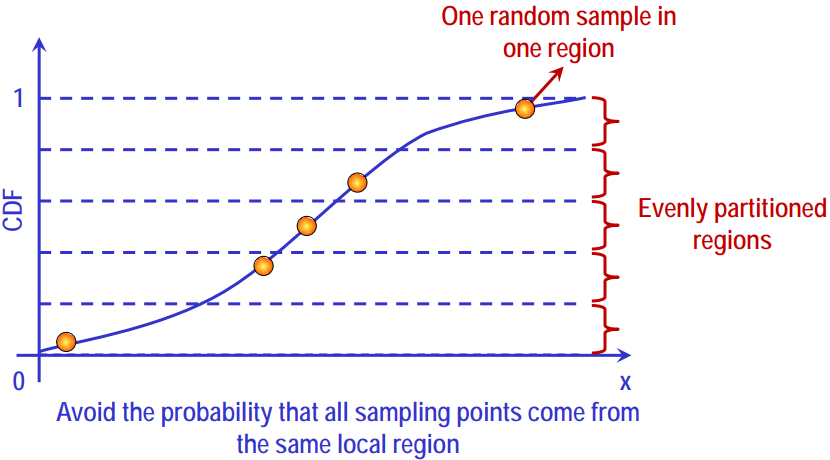
[Sampling] 라틴 하이퍼큐브 샘플링(Latin Hypercube Sampling: LHS) 1. Latin Hypercube Sampling 정의 - stratified Monte Carlo(MC)의 한 종류로 기본 아이디어는 샘플링 포인트의 분포를 확률 밀도 함수(probability density function: pdf)에 가깝게 만드는 것 - 샘플링 영역은 x의 각 구성 요소의 범위를 나누어 특정 방식으로 분할된다. x의 요소가 독립이거나, 독립을 기반으로 변형가능할 경우에만 고려한다. 특징 - 분포를 동일한 확률구간으로 분할한다. - 주로 long-running model에 사용하도록 의도됨(효율적인 계층화 특성 때문에) 2. Process process 1) x 변수로부터 샘플 크기 N을 생성한다. x1, x2, ..., xn 각 변수의 범위는 동일한 확률 크기(1/N)를 기준으로 .. Sampling 2023.02.13
How does data sparsity affect your models? 기계 학습에서 희소 데이터 세트 처리 - (analyticsvidhya.com) what is saprse datasets? missing value : null값을 포함하는 데이터 유형 sparse value : feature의 실제 값을 포함하지 않는 데이터 유형. 0과 null값을 많이 포함하는 데이터셋 문제점 머신러닝 문제에 좋지 않기 때문에 반드시 적절한 처리과정이 필요하다. 하지만, 모바일 장치에 맞게 일반 네트워크의 메모리 공간을 줄이고, 딥러닝에서 계속 증가하는 네트워크의 훈련 시간을 단축 하기 때문에 경우에 따라 좋다. 1. Overfitting (과적합) 2. Avoiding Important Data (중요한 데이터 회피) 3. Space Complexity (공간 복잡성) 4. Ti.. Machine Learning 2023.02.03
[IT신문스크랩] 11월 과기인상에 서울대 고승환 교수…"장기 모사칩 기술 연구" 본문 내용 https://www.yna.co.kr/view/AKR20221102046100017?input=1195m 더보기 (서울=연합뉴스) 문다영 기자 = 과학기술정보통신부와 한국연구재단은 이달의 과학기술인상 11월 수상자로 서울대학교 기계공학부 고승환 교수를 선정했다고 2일 밝혔다. 고 교수는 기존 장기 모사칩 제작 공정의 한계를 극복하고 시간과 비용을 크게 절감할 수 있는 '투명 실리콘 미세패터닝' 기술을 개발한 공로를 높이 평가받았다. 장기 모사칩이란 인체 장기의 생리학적 특성을 모사할 수 있는 칩으로, 인체 내 생리현상을 재현하기에 동물실험을 대체할 수 있어 신약 개발에서 중요한 기술로 평가받는다. 기존의 장기 모사칩은 준비된 틀에 실리콘 기반의 투명 탄성체인 '폴리디메틸실록산'(이하 PDMS.. IT신문스크랩 2022.11.15
[Interpolation] Interpolation (python) 1️⃣ Interpolation (보간법) https://terms.naver.com/entry.naver?docId=3405107&cid=47324&categoryId=47324 실변수 x의 함수 f(x)의 모양은 미지이나, 어떤 간격(등간격이나 부등간격이나 상관없다)을 가지는 2개 이상인 변수의 값 xi(i=1,2,…,n)에 대한 함수값 f(xi)가 알려져 있을 경우, 그 사이의 임의의 x에 대한 함수값을 추정하는 것 알고 있는 데이터 값들을 이용하여 모르는 값을 추정하는 방법의 한 종류 실험이나 관측에 의하여 얻은 관측값으로부터 관측하지 않은 점에서의 값을 추정하는 경우나 로그표 등의 함수표에서 표에 없는 함수값을 구하는 등의 경우에 이용 2️⃣ scipy.interpolate https://doc.. Machine Learning 2022.11.15
[DNN] DNN, Forward / Back Propagation (순전파 / 역전파) 1️⃣ DNN (심층 신경망) Deep Neural Network 입력층(input layer)과 출력층(output layer) 사이에 다중의 은닉층(hidden layer)을 포함하는 인공신경망(ANN) 활성화함수를 통해 비선형적 관계 학습 2️⃣ Forward Propagation (순전파) 입력층 → 은닉층 → 출력층 방향으로 학습 최종 출력값과 실제값의 오차 확인 오차함수 HTML 삽입 미리보기할 수 없는 소스 3️⃣ Back Propagation(역전파) 1. Back Propagation 순전파 알고리즘에서 발생한 오차를 줄이기 위해 새로운 가중치를 업데이트하고, 새로운 가중치로 다시 학습하는 과정 → 오차가 0 에 가까울 때까지 반복 Gradient Descent의 확장 개념 1) 임의의 .. Deep Learning 2022.11.07
[IT신문스크랩] 소리 카메라, 우주쓰레기 제거 로봇…“이것이 미래 바꿀 신기술” 본문 내용 https://www.joongang.co.kr/article/25113820 더보기 “전통 산업의 강자 중에서 디지털 전환을 가장 효과적으로 구현한 기업은 스타벅스일 듯합니다. 매장에 방문하기 전 주문과 결제를 마칠 수 있는 ‘사이렌 오더’ 서비스와 자체 애플리케이션을 통한 리워드 프로그램을 통해서지요. 올해 들어 스타벅스의 선불카드 충전 잔액이 국내에서만 3400억원, 미국 본사는 2조4000억원에 달합니다.” 지난 27일 서울 강남구 삼성동 코엑스에서 열린 ‘미래유망기술 콘퍼런스’ 행사장. 김지현 SK마이써니 부사장은 “스타벅스는 이미 커피 회사가 아니라 디지털 금융 기업”이라며 “디지털 기술을 기반으로 새로운 가치를 창출하는 게 4차 산업혁명의 핵심”이라고 강조했다. 스타벅스처럼 전통적.. IT신문스크랩 2022.11.02
[Text Summarization] 1. TextRank 2004년 제안 키워드 추출 기능 + 핵심 문장 추출 기능 1. 키워드 추출 기능 단어 그래프 사용(명사, 동사, 형용사와 같은 단어만 사용) 최소 빈도수 + 문장 + 토크나이저 유사도 → 두 단어의 co-occurrence 계산(두 단어 간격이 window인 횟수(2~8)) 2. 핵심 문장 추출 기능 문장 간 유사도 측정 : 두 문장에 공통으로 등장한 단어의 개수를 각 문장의 단어 개수의 log 값의 합으로 나눈 값 문장의 길이가 길수록 높은 유사도 자주 등장하는 단어가 많이 포함될 수록 유사도 증가 Cosine similarity 는 길이가 짧은 문장에 민감 LexRank (Erkan at al., 2004) 는 TF-IDF + Cosine similarity 이용 (결과 크게 다르지 않음) *참고 .. NLP 2022.10.17